
El sector del transporte está adoptando tecnologías y técnicas avanzadas a un ritmo vertiginoso. Se ha producido una explosión de empresas que promocionan ideas innovadoras y basadas en datos, así como un gran número de empresas que ofrecen herramientas de apoyo al análisis predictivo, como la IA y la tecnología de aprendizaje automático. Por un lado, esto es muy emocionante, ya que el uso generalizado del análisis predictivo desempeñará un papel clave en el avance de la industria. Por otro lado, esta tecnología puede resultar desalentadora para alguien que conozca el transporte de mercancías y la logística, pero que no tenga formación en matemáticas, estadística o informática.
Para guiarle, aquí tiene algunas preguntas clave que debe plantearse cuando considere soluciones de análisis predictivo, aprendizaje automático o IA:
¿Su precisión de predicción incluye los verdaderos negativos? ¿O sólo los verdaderos positivos?
Esta es la pregunta más importante que hay que hacer a una empresa que pronostica algo que podría clasificarse como un sí o un no. Por ejemplo, ¿se entregará a tiempo la carga en tránsito? Muchas empresas afirman que sus predicciones son exactas. Desgraciadamente, esto no dice mucho, porque hay dos maneras de acertar y dos maneras de equivocarse.
Por ejemplo, cuando se predice que una carga va a llegar a tiempo y llega a tiempo, esto se denomina un verdadero positivo y es la fuente más probable de una afirmación exagerada de precisión. Para separar los resultados aleatorios de las predicciones útiles, también debemos ser capaces de predecir los verdaderos negativos. Así, si una empresa predijo que todas las cargas llegarían a tiempo y el 86% de las cargas llegan a tiempo, esto significaría que se produjo un verdadero positivo el 86% de las veces con una tasa de verdaderos negativos del 0%. En este ejemplo, el 14% de las cargas no llegaron a tiempo, pero como el algoritmo de la empresa predijo que todas las cargas llegarían a tiempo, no predijo correctamente los verdaderos negativos. Una puntuación perfecta predeciría con exactitud el 86% de las cargas puntuales y el 14% de las no puntuales. Como mínimo, la empresa debería poder indicarle su capacidad para predecir verdaderos positivos y verdaderos negativos. Mejor aún, podrían elaborar una tabla de predicción como ésta:
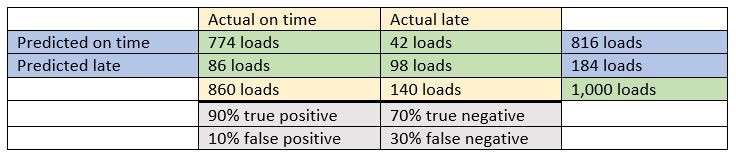
¿Incluyen sus predicciones una medición fuera de la muestra?
En general, los modelos predictivos utilizan datos históricos para predecir lo que ocurrirá en el futuro. Para medir el rendimiento de un modelo, es fundamental probarlo con datos que no se hayan utilizado para crearlo. Esto requiere utilizar datos fuera de la muestra para medir la precisión. Los algoritmos predictivos que se miden sin utilizar un enfoque fuera de la muestra producirán casi universalmente resultados inflados. Por ejemplo, supongamos que el modelo predice los costes de los camiones de carga en el mercado al contado, y estamos midiendo lo bien que el modelo predijo las tarifas al contado de la semana pasada. Si los datos de la semana pasada se incluyen en el conjunto de datos utilizado por el modelo, éste ve lo que está prediciendo dentro de los datos que está utilizando. Esencialmente, el modelo está "haciendo trampas" al conseguir ver los datos que se supone que debe predecir. Para tener una idea realista del rendimiento del modelo, siempre debe medirse utilizando datos fuera de la muestra.
Si la empresa mide algo con valores continuos, como los costes, y presenta un valor de precisión porcentual, ¿es ese valor el error porcentual medio (EMP) o el error porcentual medio absoluto (EMPA)?
La última de las tres preguntas puede ser la más técnica, pero debe resultar intuitiva. Supongamos que la empresa predice los precios al contado de los camiones de carga y dice que su error medio es del 1,5%. Suena bien, ¿verdad? Pero, ¿es así? Lo más probable es que informen de su error porcentual medio (EMP). Esto toma todas las predicciones, las compara con las reales, las convierte en porcentaje y calcula la media. Por ejemplo, supongamos que tenemos dos cargas que cuestan 1.000 dólares. Si el modelo disparó demasiado alto por $ 500 en una carga y luego demasiado bajo por $ 500 en la siguiente, tendríamos un error positivo del 50% y un error negativo del 50%, que promedia a cero. Pero, ¿estaría contento con un error de 500 dólares en cada carga?
Necesita una medida adicional denominada error porcentual medio absoluto (MAPE). Es similar al error medio absoluto, pero no permite que los valores positivos y negativos se anulen entre sí. Para el MAPE, un error es un error independientemente de la dirección. Se trata de una medida de error más dura y, en el ejemplo anterior, nuestro MAPE sería del 50%.
Para comprender plenamente la precisión de un modelo, se necesitan ambos valores. El MPE da una idea de lo centradas que están las predicciones del modelo, y el MAPE indica lo dispersos que están los errores. Es fundamental ver los dos valores de una empresa con la que esté pensando trabajar, no sólo uno.
Con el avance del análisis predictivo y otras herramientas, estamos en un momento apasionante en el sector de la logística. Armado con estas preguntas, deberías estar un paso más cerca de convertirte en un consumidor experto de estas herramientas y técnicas, y los expertos de Echo siempre están aquí para ayudarte en el camino.
Tanto si es un cargador como un transportista, la tecnología avanzada de Echo aprovecha lo último en IA, aprendizaje automático y algoritmos avanzados de correspondencia de cargas para crear el sistema de gestión de transporte más flexible y sólido disponible en la actualidad. La tecnología líder del sector de Echo, que se basa en nuestra arquitectura de vanguardia, permite el despliegue rápido de nuevas capacidades y se integra con los sistemas del cargador, del transportista y de terceros.
Para obtener más información sobre la tecnología de automatización y análisis, póngase en contacto con Echo hoy mismo en el 800-354-7993 o en info@echo.com.
A título informativo.

